
译者注:最近 Python 3.12 引入了子解释器概念,非常火热,更好的消息是已经在FastAPI应用成功了,虽然是很简单的那种。因此顺腾摸瓜,找到了作者的博客,翻译分享给大家。
Python 3.12 引入了一个新的 API 用于“子解释器”(sub interpreters),这是 Python 的一种不同的并行执行模型,提供了真正并行处理和多进程处理之间的良好折中,且具有更快的启动时间。在这篇文章中,我将解释什么是子解释器,为什么它对 Python 中的并行代码执行很重要,以及它与其他方法的比较。
什么是子解释器?
Python 的系统架构大致由三部分组成:
- 一个包含一个或多个解释器的 Python 进程
- 一个包含锁(GIL)和一个或多个 Python 线程的解释器
- 一个包含当前执行代码信息的线程。
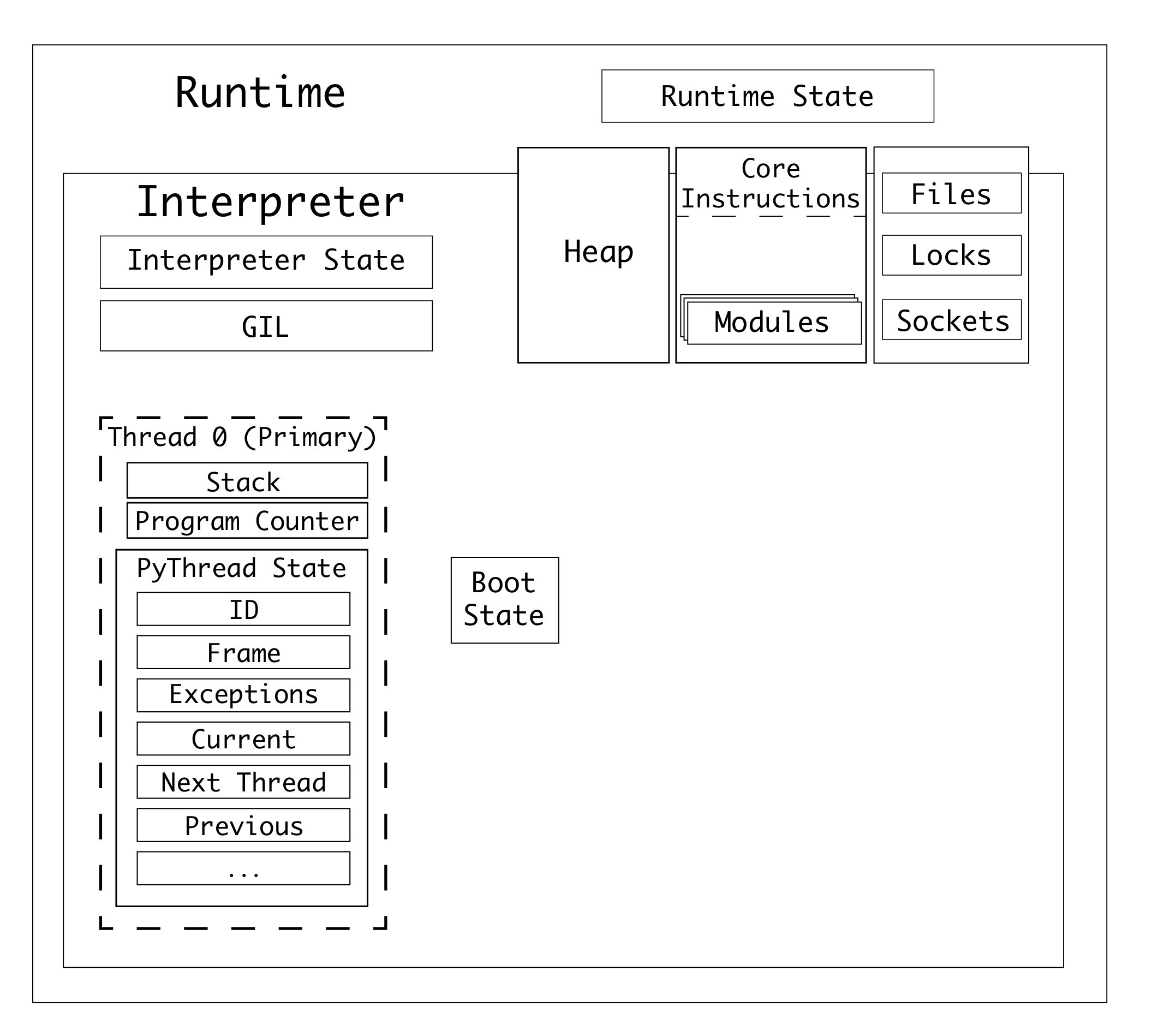
要了解更多关于这方面的信息,你可以阅读我的书《CPython 内部实现》中的“并行性和并发性”章节。
自 Python 1.5 以来,就有一个 C-API 可以支持多个解释器,但这个功能由于 GIL 的限制而受到严重限制,没有真正实现真正的并行性。因此,运行并行代码最常用的技术(不使用第三方库)是使用 multiprocessing 模块。
2017 年,CPython 核心开发人员提出改变解释器结构的提议,使它们更好地与拥有它们的 Python 进程隔离,并能够并行操作。实现这一目标的工作相当巨大(6 年后仍未完成),并分为两个 PEP。PEP684 将 GIL 在各个解释器独立开,PEP554 提供了一个创建解释器和在它们之间共享数据的 API。
GIL 是“全局解释器锁”,是 Python 进程中的一个锁,意味着在任何时间点 Python 进程中只能执行一条指令,即使它有多个线程。这实际上意味着,即使你在拥有 4 核 CPU 的电脑上同时启动 4 个 Python 线程,也只有一个线程会在任何时候运行。

你可以通过创建一个 numpy 数组或整数,并粗略计算每个值与 50 的距离来进行一个简单的测试:
import numpy
# Create a random array of 100,000 integers between 0 and 100
a = numpy.random.randint(0, 100, 100_000)
for x in a:
abs(x - 50)
理论上,你会期望(至少在像 C 语言这样的语言中),通过将工作分割成块并将工作分配给线程,执行时间会更快:
import numpy, threading
a = numpy.random.randint(0, 100, 100_000)
threads = []
# Split array into blocks of 100 and start a thread for each
for ar in numpy.split(a, 100):
t = threading.Thread(target=simple_abs_range, args=(ar,))
t.start()
threads.append(t)
for t in threads:
t.join()
实际上,在第二个例子中,执行速度是第一个的两倍慢。这是因为所有这些线程都绑定到同一个 GIL,且任何时候只有一个线程会执行。额外的时间全部花在了启动线程上,却几乎没完成什么实质工作。
尽管名为 GIL(全局解释器锁),但它实际上从来不是解释器状态中的真正锁。PEP684 通过停止在解释器之间共享 GIL 来改变这一点,使得 Python 进程中的每个解释器都有自己的 GIL,因此可以并行运行。per-interpreter GIL 工作耗时多年的主要原因是 CPython 在内部依赖 GIL 作为线程安全的来源。这表现为许多 C 扩展具有全局共享状态。如果在同一 Python 进程中引入并行性,并且两个解释器尝试写入同一内存空间,就会发生糟糕的事情。
在 Python 3.12 中,以及 Python 3.13 中正在进行的工作中,Python 标准库中用 C 语言编写的扩展正在被测试,并且任何全局共享状态都正在被移动到一个新的 API 中,该 API 将该状态放在模块内或解释器状态内。即使这项工作完成后,第三方 C 扩展可能也需要在子解释器中进行测试(我维护的一个用 C++编写的库就需要修改)。
关于移除 GIL 的工作怎么样了?这不会让之前的工作变得无关紧要吗?
最近批准的提案 PEP703,旨在使 CPython 中的 GIL 成为可选项,与 per-interpreter GIL 的工作相辅相成。这两个提案都有以下先决条件:
- Immortal Objects
- 更新 C 扩展以避免使用共享的全局状态
另一个重要点是,尽管 PEP703 已被接受,但它是作为一个可选标志进行的,如果证明过于复杂或问题重重,则未来可能会撤销这些更改。另一方面,per-interpreter GIL 的工作基本上已经完成,并且不需要在 CPython 中使用另一个编译时标志。
关于 PEP703,我将来会写更多内容。在这篇文章的后面,我会分享一些代码,我将尝试将这两种方法结合起来。
线程、多进程和子解释器之间有什么区别?
Python 标准库提供了一些并发编程的选项,这取决于一些因素:
- 您正在完成的任务是否是 IO 绑定的(例如,从网络读取,写入磁盘)
- 任务是否需要大量的 CPU 计算
- 任务是否可以分解为小块,或者它们是大块的工作?
这里是不同的模型:
- 线程创建快速,你可以在它们之间共享任何 Python 对象,且开销小。缺点是 Python 线程绑定到进程的 GIL,所以如果工作负载是 CPU 密集型的,你不会看到任何性能提升。线程非常适合后台轮询任务,比如一个等待并监听队列上消息的函数。
- 协程创建极快,你可以在它们之间共享任何 Python 对象,且开销极小。协程是基于 IO 活动的理想选择,尤其是那些支持 async/await 的底层 API。
- 多进程是 Python 的一个包装器,用于创建 Python 进程并将它们链接在一起。这些进程启动缓慢,所以你给它们的工作量需要足够大,才能看到并行化工作的好处。然而,它们是真正的并行,因为每个进程都有自己的 GIL。
- 子解释器具有多进程的并行性,但启动时间更快。
我在 2023 年 PyCon APAC 上关于这个话题做了一个演讲,你可以查看那个演讲以获得详细的口头解释。
或者,用表格来表示:
:–|:–|:–|:– Model|Execution|Start-up time|Data Exchange threads|Parallel*|small|Any coroutines|Concurrent|smallest|Any Async functions|Concurrent|smallest|Any Greenlets|Concurrent|smallest|Any multiprocessing|ParalleL|large|Serialization Sub Interpreters|Parallel|medium|Serialization or Shared Memory
* 正如我们探讨的,线程仅在 IO 绑定任务中是并行的。
子解释器在实际性能方面如何比较?
在一个简单的基准测试中,我测量了创建以下内容的时间:
- 100 个线程
- 100 个子解释器
- 使用多进程的 100 个进程
以下是结果:
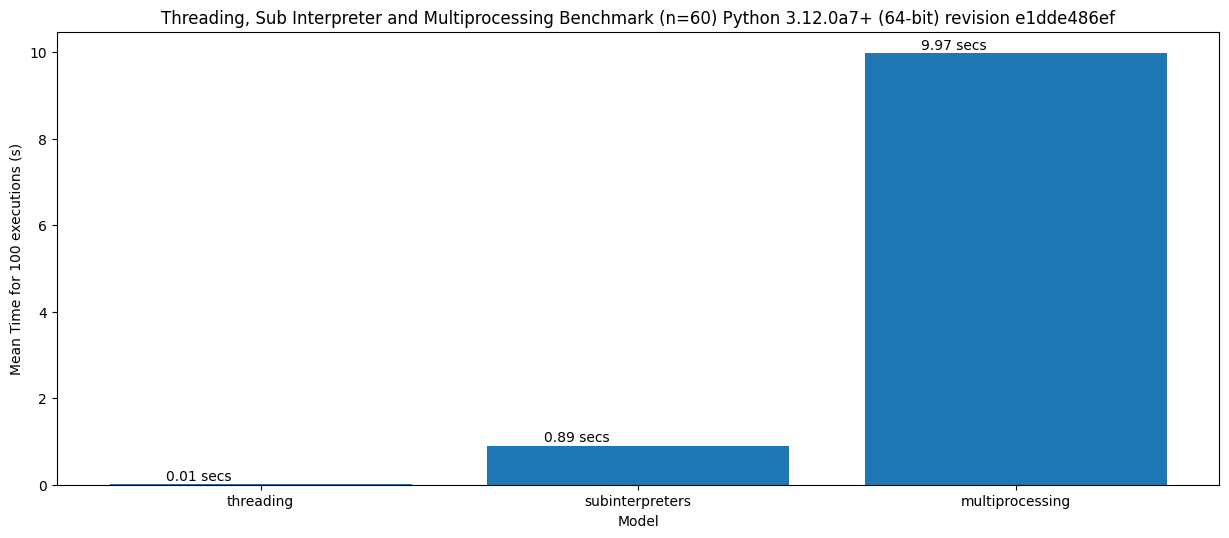
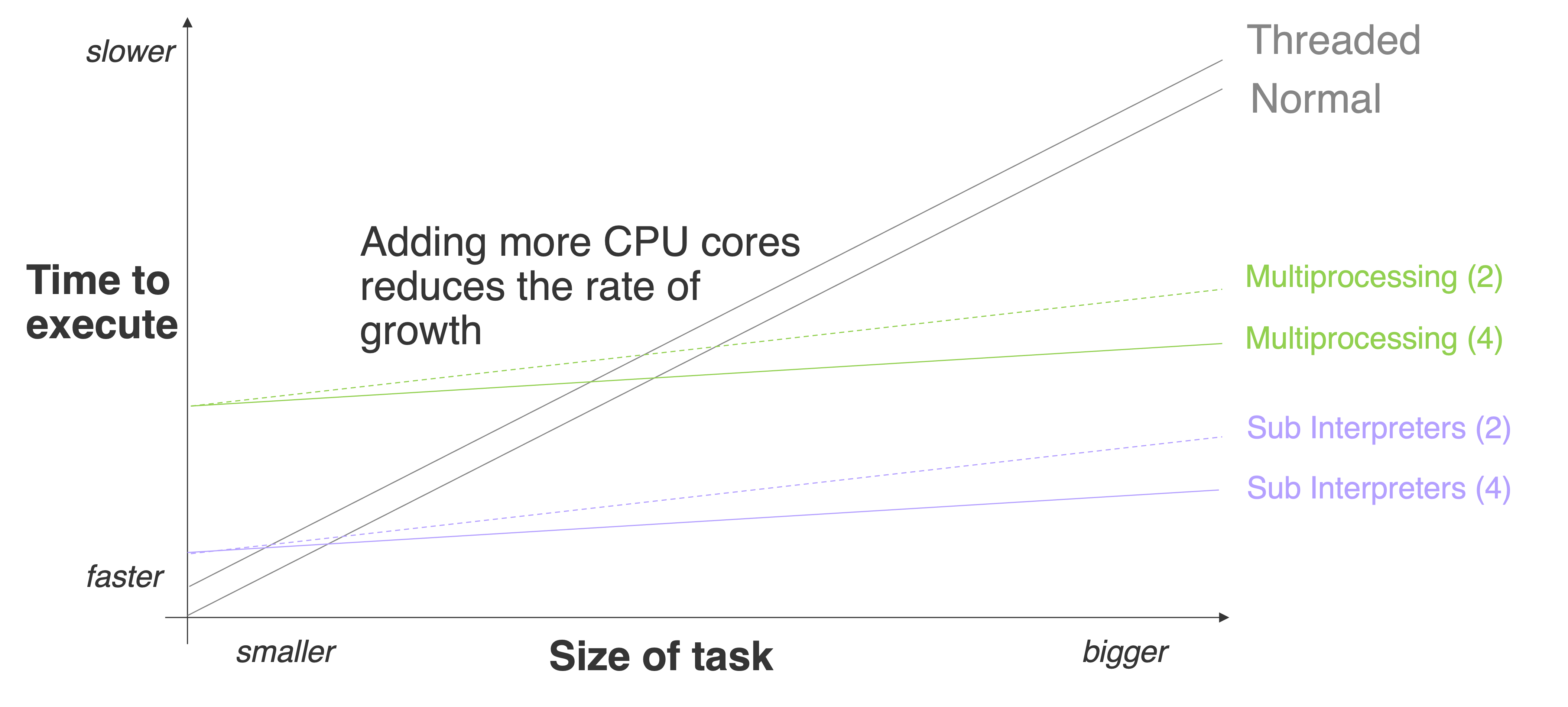
这个基准测试显示,线程启动的速度大约比子解释器快 100 倍,而子解释器的启动速度则比多进程快大约 10 倍。我希望这个图表能清楚地表明,与多进程相比,解释器与线程有多么接近。
这个基准测试也没有衡量数据共享的性能(在子解释器中比多进程快得多)以及内存开销(同样显著减少)。
不并行运行任何东西并不是一个非常有用的基准测试,除了用于测量最小启动时间之外。接下来,我对一个 CPU 密集型的工作负载进行了基准测试,计算 Pi 到 2000 个小数位。
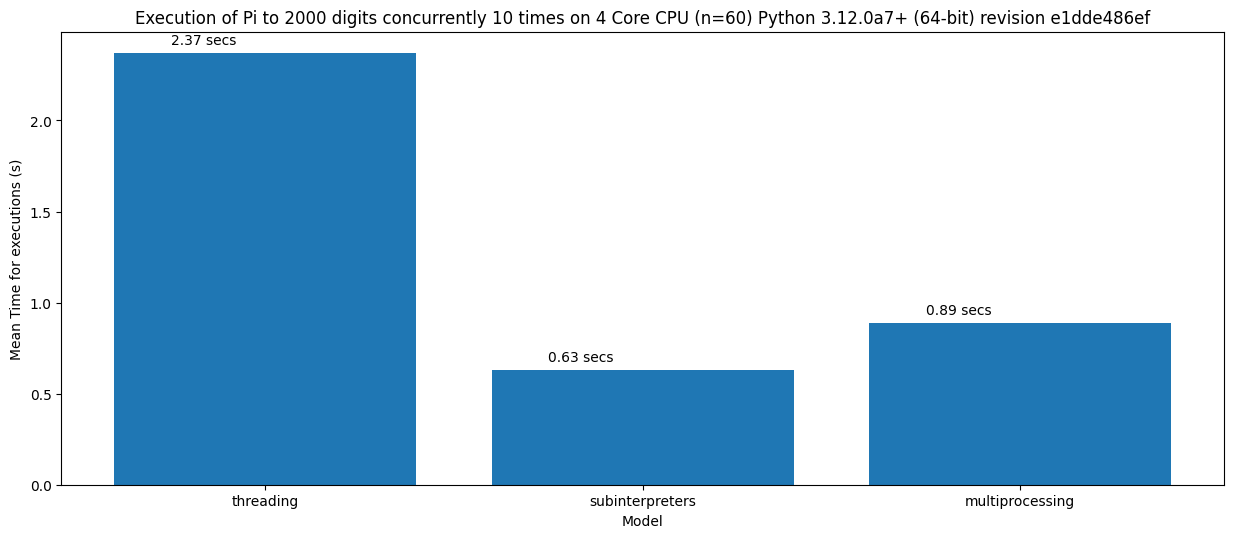
很好!那么所有并行工作负载使用子解释器都会更快吗?
遗憾的是,并非如此。回到第一个基准测试,子解释器的启动速度仍然比线程慢 100 倍。所以,如果任务真的很小,例如计算 Pi 到 200 位数字,那么并行性的好处会超过启动开销,线程仍然更快:
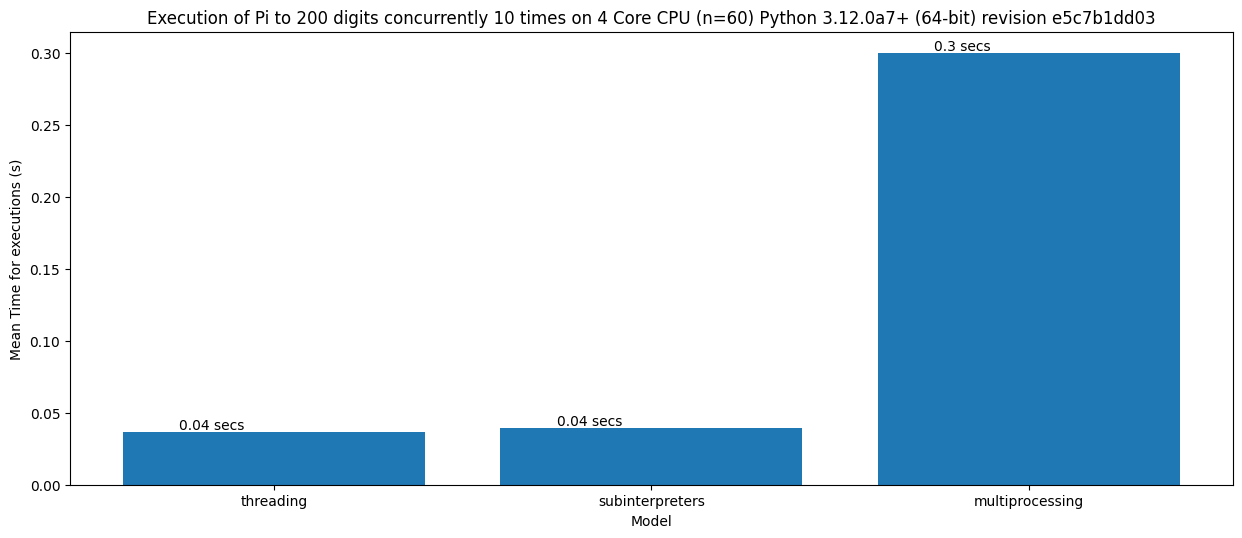
为了直观地解释存在一个“临界点”,在该点上并行性变得更快的概念,这张图展示了工作量大小和执行时间增长速率。临界时间并不是一个固定值,因为它取决于 CPU、后台任务和许多其他变量。
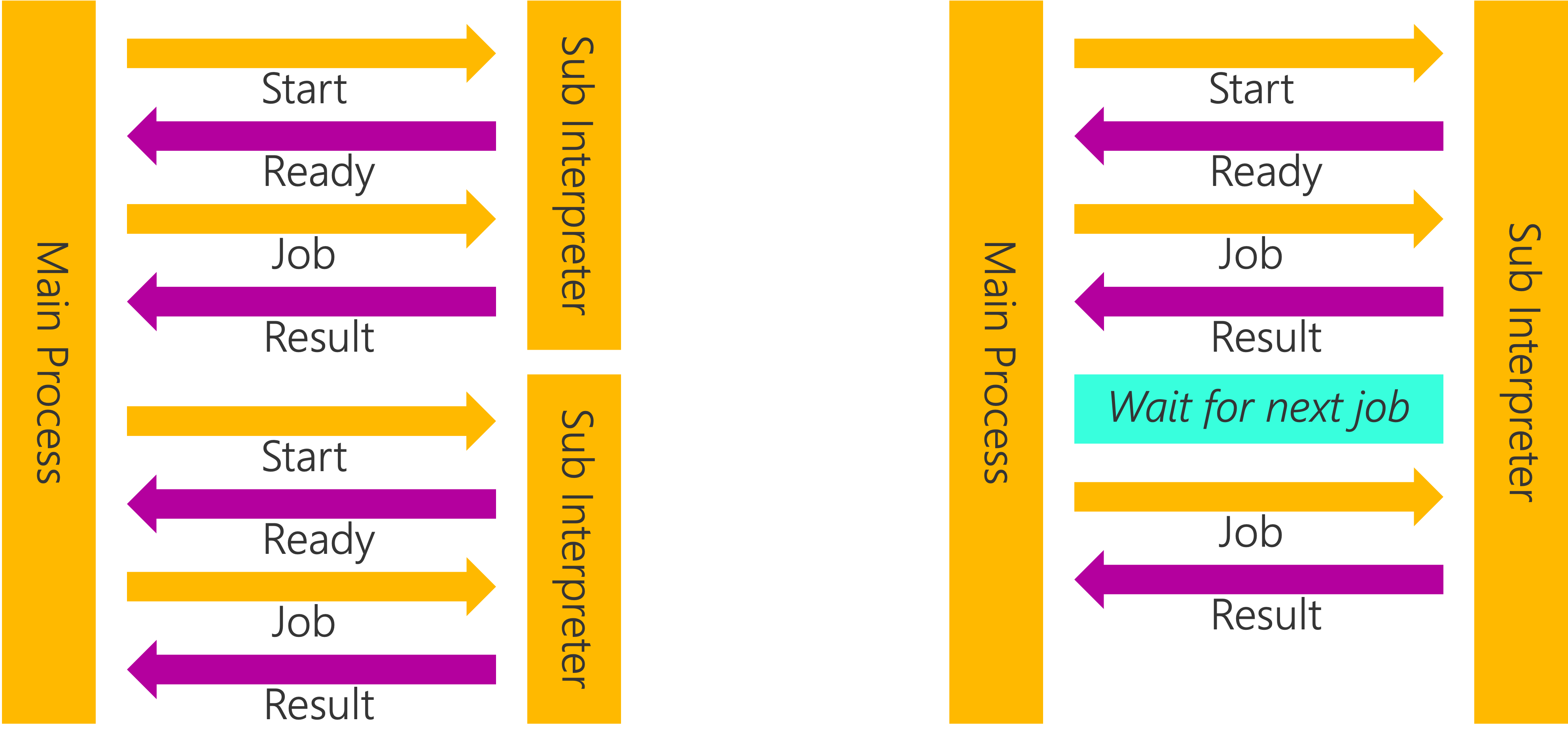
另一个重要的观点是,多进程通常被用于一种模型,其中进程长时间运行并处理大量任务,而不是为了单个工作负载而被创建和销毁。一个很好的例子是 Gunicorn,这是一个流行的 Python 网络服务器。Gunicorn 将使用多进程技术生成“工作进程”,这些工作进程将存活于主进程的整个生命周期。当网络工作进程可能运行数周、数月甚至数年时,启动进程或子解释器的时间(分别是 89 毫秒或 1 秒)就变得无关紧要。对于小任务(如处理单个网络请求)使用这些并行工作进程的理想方式是保持它们运行,并使用主进程来协调和分配工作负载:
当您使用多进程或子解释器时,每个进程或解释器都有自己的导入状态。这与线程和协程截然不同。当您等待一个异步函数时,您不需要担心该协程是否已经导入了所需的模块。线程也是如此。例如,您可以在模块中导入某些内容,并从线程函数内部引用它:
import threading
from super.duper.module import cool_function
def worker(info):
cool_function() # This already exists in the interpreter state
info = {'a': 1}
thread = Thread(target=worker, args=(info, ))
启动解释器所需时间的一半用于执行“site import”。这是一个名为 site.py 的特殊模块,位于 Python 安装目录中。解释器拥有自己的缓存和内置模块,它们实际上是迷你的 Python 进程。启动线程或协程之所以如此快速,是因为它们不需要执行这些初始化工作(它们与拥有它们的解释器共享状态),但它们受限于锁并且不是并行的。
在解释器和进程已经启动并运行后,对性能有影响吗?
当使用像多进程或子解释器这样的并行执行模型时,下一个考虑点是如何共享数据。一旦克服了启动的障碍,这很快就成为最重要的问题。你需要回答两个问题:
- 我们如何在工作进程间通信?
- 我们如何管理工作进程的状态?
我们分别来讨论这些问题。
工作进程间通信
无论是使用子解释器还是多进程,你都不能简单地向工作进程发送现有的 Python 对象。
多进程默认使用 pickle。当你启动一个进程或使用进程池时,你可以使用管道、队列和共享内存作为向工作进程和主进程发送/接收数据的机制。这些机制都围绕着 pickle。Pickle 是 Python 的内置序列化库,可以将大多数 Python 对象转换为字节字符串,然后再转换回 Python 对象。
Pickle 非常灵活。你可以序列化许多不同类型的 Python 对象(但不是全部),Python 对象甚至可以定义它们如何被序列化的方法。它还处理嵌套对象和属性。然而,随着这种灵活性带来了性能损失。Pickle 是缓慢的。因此,如果你有一个依赖于持续的工作进程间复杂 pickled 数据通信的工作模型,你可能会看到瓶颈。
子解释器可以接受 pickled 数据。它们还有第二种机制叫做共享数据。共享数据是一个高速共享内存空间,解释器可以写入并与其他解释器共享数据。它只支持不可变类型,这些是:
- 字符串
- 字节字符串
- 整数和浮点数
- 布尔值和 None
- 元组(及元组的元组)
我上周实现了元组共享机制,以便我们有一些序列类型的选项。
要与解释器共享数据,你可以将其设置为初始化数据,或者通过一个通道发送。
工作进程状态管理
对于子解释器来说,这是一个正在进行的工作。如果子解释器崩溃,它不会杀死主解释器。异常可以被提升到主解释器并优雅地处理。这方面的细节仍在研究中。
如何使用子解释器?
在 Python 3.12 中,子解释器 API 是实验性的,我要提到的一些东西只在一周前实现,还没有发布,所以你会在未来的 3.13 版本中看到它们。如果你想编译 CPython 的主分支,你可以自己操作。
PEP554 提出的 interpreters 模块尚未完成。它的一个版本是一个秘密的、隐藏的模块,叫做_xxsubinterpreters。在我所有的代码中,我将导入重命名为interpreters,因为这将是它在将来的名称。
你可以使用``.run()`函数创建、运行和停止子解释器,该函数接受一个字符串或一个简单的函数。
import _xxsubinterpreters as interpreters
interpreters.run('''
print("Hello World")
''')
启动子解释器是一个阻塞操作,因此大多数时候你需要在一个线程内启动它。
from threading import Thread
import _xxsubinterpreters as interpreters
t = Thread(target=interpreters.run, args=("print('hello world')",))
t.start()
要启动一个持续存在的解释器,你可以使用 interpreters.create(),它会返回解释器 ID。这个 ID 可以用于后续的 ``.run_string` 调用:
import _xxsubinterpreters as interpreters
interp_id = interpreters.create(site=site)
interpreters.run_string(interp_id, "print('hello world')")
interpreters.run_string(interp_id, "print('hello universe')")
interpreters.destroy(interp_id)
为了共享数据,你可以使用 shared 参数并提供一个带有可共享值(int, float, bool, bytes, str, None, tuple)的字典:
import _xxsubinterpreters as interpreters
interp_id = interpreters.create(site=site)
interpreters.run_string(
interp_id,
"print(message)",
shared={
"message": "hello world!"
}
)
interpreters.run_string(
interp_id,
"""
for message in messages:
print(message)
""",
shared={
"messages": ("hello world!", "this", "is", "me")
}
)
interpreters.destroy(interp_id)
一旦解释器开始运行(记住我所说的最好让它们持续运行),你可以使用通道共享数据。通道模块也是 PEP554 的一部分,可以通过秘密导入使用:
import _xxsubinterpreters as interpreters
import _xxinterpchannels as channels
interp_id = interpreters.create(site=site)
channel_id = channels.create()
interpreters.run_string(
interp_id,
"""
import _xxinterpchannels as channels
channels.send('hello!')
""",
shared={
"channel_id": channel_id
}
)
print(channels.recv(channel_id))
Web 应用中的并行工作机制
Web 应用中多进程和多线程模型的应用,Python Web 服务器,如用于 Django、Flask、FastAPI 或 Quart 的服务器,使用称为 WSGI 的接口来处理传统 Web 框架,而对于异步框架则使用 ASGI。这些 Web 服务器监听 HTTP 端口上的请求,然后将请求分配给一组工作进程。如果只有一个工作进程,那么当一个用户发出 HTTP 请求时,其他用户必须等待,直到它响应完第一个请求(这也是为什么你不应该将 python manage.py runserver 作为 Web 服务器的原因,因为它只有一个工作进程)。
Gunicorn 建议的最佳实践是运行多个 Python 进程,由一个主进程协调,并且每个进程都有一个线程池:
- 使用多进程启动多个工作进程(通常每个 CPU 核心一个工作进程)
- Web 请求被分配给一个线程池
这种设计(有时被称为多工作进程-多线程)意味着通过使用多进程,你会为每个 CPU 核心拥有一个 GIL,并且拥有一个线程池来并发处理进入的请求。Uvicorn(异步实现)在此基础上通过使用协程来处理并发,并支持异步框架。
这种方法有一些缺点。正如我们之前探讨的,线程并不是并行的,所以如果你在单个工作进程中有 2 个线程非常繁忙,Python 无法“移动”或在不同的 CPU 核心上调度该任务。
应用子解释器到 Web 应用中
我的目标是用解释器替换多进程作为工作进程的机制。这样做的好处是可以使用高性能的共享内存通道 API 进行工作进程间通信,并且工作进程会更轻量级,占用较少的主机内存(从而留出更多内存和资源来处理请求)。
另一个相当大胆的目标是编译 CPython 3.13(主分支)并使用 PEP703 中的无 GIL 线程实现,以查看我们是否可以在这个模型中运行无 GIL 线程。我还希望及早识别问题(确实有几个问题)并向上游报告。
为此,我尝试对 Gunicorn 进行分支操作,用子解释器替换多进程。我发现这将是一项巨大的努力,因为 Gunicorn 确实有“工作进程”的概念,并且在一个称为工作类的接口中对其进行了抽象。然而,它对工作类的能力做了一些假设,而子解释器并不满足这些假设。
有人在 Mastodon 上建议我检查 Hypercorn,结果发现它非常适合这次测试。Hypercorn 有一个异步工作模块,其中包含一个可以从解释器内部导入的可调用对象。我需要解决的问题是:
- 工作进程如何共享套接字?
- 如何让一个工作进程干净地关闭(异步事件在解释器间不起作用)?
于是我遵循了下面的设计:
- 创建一个解释器
- 创建一个信号通道以发送关闭请求
- 子类化
threading.Thread类并实现一个自定义的.stop()方法,该方法向子解释器发送信号 - 在一个线程中运行每个子解释器
- 将套接字列表转换为元组的元组
工作类的大致外观如下:
class SubinterpreterWorker(threading.Thread):
def __init__(self, number: int, config: Config, sockets: Sockets):
self.worker_number = number
self.interp = interpreters.create()
self.channel = channels.create()
self.config = config # TODO copy other parameters from config
self.sockets = sockets
super().__init__(target=self.run, daemon=True)
def run(self):
# Convert insecure sockets to a tuple of tuples because the Sockets type cannot be shared
insecure_sockets = []
for s in self.sockets.insecure_sockets:
insecure_sockets.append((int(s.family), int(s.type), s.proto, s.fileno()))
interpreters.run_string(
self.interp,
interpreter_worker,
shared={
'worker_number': self.worker_number,
'insecure_sockets': tuple(insecure_sockets),
'application_path': self.config.application_path,
'workers': self.config.workers,
'channel_id': self.channel,
}
)
def stop(self):
print("Sending stop signal to worker {}".format(self.worker_number))
channels.send(self.channel, "stop")
子解释器守护程序代码 (interpreter_worker):
import sys
sys.path.append('experiments')
from hypercorn.asyncio.run import asyncio_worker
from hypercorn.config import Config, Sockets
import asyncio
import threading
import _xxinterpchannels as channels
from socket import socket
import time
shutdown_event = asyncio.Event()
def wait_for_signal():
while True:
msg = channels.recv(channel_id, default=None)
if msg == "stop":
print("接收到停止信号,关闭 {} ".format(worker_number))
shutdown_event.set()
else:
time.sleep(1)
print("在子解释器 {} 中启动hypercorn工作进程 ".format({worker_number}))
_insecure_sockets = []
# 从元组中重建套接字列表
for s in insecure_sockets:
_insecure_sockets.append(socket(*s))
hypercorn_sockets = Sockets([], _insecure_sockets, [])
config = Config()
config.application_path = application_path
config.workers = workers
thread = threading.Thread(target=wait_for_signal)
thread.start()
asyncio_worker(config, hypercorn_sockets, shutdown_event=shutdown_event)
完整代码可在GitHub 上找到。
发现
我的首次尝试还没有在子解释器中实现多线程(除了信号线程外)。我正在构建并测试 CPython 的一个不稳定版本,且处于调试模式。目前尚未准备好进行性能对比测试。
PEP703 尚未完成。GitHub 上100 多个待办事项清单大约完成了 50%。只有在完成这个清单后,才能禁用 GIL。
我还发现了一些问题。首先,Django 根本无法运行。记得在本文前面我提到过,一些 Python C 扩展使用全局共享状态吗?datetime就是这样的模块之一。虽然有一个 issue 是更新它,但目前还未合并。其后果是,如果你从子解释器中导入zoneinfo,它将失败。Django 使用zoneinfo,所以它甚至无法启动。
我在一个非常简陋的 FastAPI 和 Flask 应用程序上有更多的运气。我能够启动 2、4 和 10 个工作进程的设置。我对 FastAPI 和 Flask 应用程序进行了一些基准测试,以查看它们如何处理 10,000 个请求,同时并发量为 20。两者都表现出色,我的所有 CPU 核心都在忙碌工作。
我感到非常惊讶,因为我根本没有期望它会工作,因为子解释器是如此新颖,且 Python 生态系统还没有对它们进行测试。下一步是测试更复杂的 Web 应用程序,继续报告崩溃和问题,然后让这个 Web 工作进程稳定到足以进行基准测试的状态。
然后,我可能会为 Hypercorn 提交一个 PR,以便于适配明年发布的 Python 3.13。
