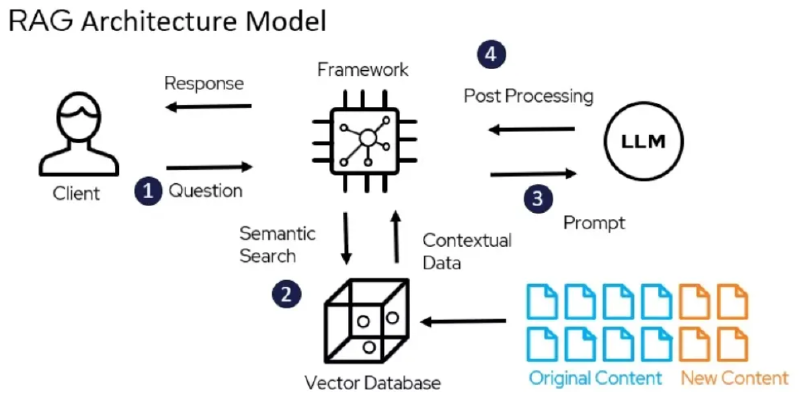
检索增强生成(Retrieval Augmented Generation,简称RAG)技术正逐渐成为提升大型语言模型(LLM)性能的关键。OpenAI 的 John Allard 和 Colin Jarvis 在一场分享中,以实际案例为基础,深入浅出地讲解了如何将 RAG 技术应用于实际工程问题,并分享了他们的最佳实践经验。这些内容对于 RAG 技术的应用者来说,无疑是非常有价值的。事实上,OpenAI 开放了很多的他们的最佳实践内容,包括不限于 Prompt Engineering、Data Augmentation、Fine-tuning、Inference Optimization 等等。有空除了多看一下相关论文,OpenAI 的 Github 和 Youtube 频道都值得看一下。比如说这次分享就是来源于 OpenAI 的 Youtube 频道。
优化 LLM 性能的挑战
优化 LLM 性能并非易事,哪怕丁点的区别都可能导致结果上出现很大的差异。目前优化性能主要存在以下挑战:
- 难以确定问题根源: LLM 的输出结果受多种因素影响,如提示工程、训练数据、模型架构等。当模型性能不佳时,难以从这些复杂的交互中分离出导致问题的具体原因。
- 难以衡量性能: 对于许多 LLM 应用,例如文本摘要、问答系统等,难以找到一个客观的、可量化的指标来准确评估模型的性能。
- 难以选择优化方法: 即使确定了问题,也难以选择最合适的优化方法。开发者需要根据具体问题选择合适的技术,例如提示工程、微调、RAG 等。
OpenAI 的优化框架
为了解决上述挑战,OpenAI 提出了一个二维优化框架,将优化方向分为__内容优化__和__LLM优化__两个部分。
内容优化
内容优化指的是优化模型可访问的知识内容。如果模型缺乏必要的知识或信息质量较差,那么即使模型本身的能力很强,也难以给出令人满意的答案。
为了补全这部分的知识内容,可以采用以下方法进行:
- RAG: 将外部知识库与 LLM 集成,允许模型访问更广泛、更专业的知识。
- 数据增强: 通过对现有数据进行扩展或转换,增加训练数据的数量和多样性。
- 数据清洗: 识别和纠正训练数据中的错误或噪声,提高数据质量。
LLM 优化
通过优化模型本身提升效果。如果模型本身存在缺陷,例如容易产生幻觉或难以理解复杂指令,那么即使有充足的知识,也难以给出合理的答案。
在这个优化方案中,可以采用下面的方式进行:
- 提示工程: 通过设计更清晰、更明确的提示,引导模型生成符合预期的输出。
- 微调: 使用特定任务的数据集对预训练模型进行进一步训练,使模型更适应特定任务。
- 模型架构优化: 调整模型的架构或参数,提高模型的学习能力和泛化能力。
OpenAI 的建议
在这个框架下,OpenAI 建议开发者采用以下流程进行优化:
- 从提示工程开始: 提示工程是快速测试和学习的最佳起点,它可以帮助开发者快速验证解决问题的可行性,并初步了解模型的能力和缺陷。
- 根据评估结果选择优化方向: 通过评估模型的输出,开发者可以判断问题是出在内容上还是 LLM 本身。例如,如果模型经常给出与事实不符的答案,则可能是内容方面的问题;如果模型难以理解复杂指令,则可能是 LLM 本身的问题。
- 迭代优化: 优化 LLM 性能是一个迭代的过程,开发者可能需要在不同的优化技术之间来回切换,不断尝试和调整,才能最终达到满意的效果。
RAG 技术的应用场景
RAG 技术主要用于解决内容优化方面的问题,它允许模型访问特定领域的内容,从而提高模型的知识储备和回答问题的准确性。OpenAI 分享了两个经典案例,展示了 RAG 技术在实际工程中的应用,以及他们如何根据优化框架逐步提高模型性能。
案例一:基于特定文档的知识检索
客户希望模型基于 10 万份文档进行知识检索。最初,直接嵌入文档的准确率只有 45%。在对模型性能进行评估后,OpenAI 团队发现问题主要出在内容方面:模型难以从大量的文档中找到最相关的信息,并且对部分文档的理解存在偏差。
于是,OpenAI 团队根据下面的方式进行了进一步的优化,帮助进行提升:
- 尝试回答并对答案进行向量搜索: 通过制定规则,例如先判断问题所属领域进行回答,再进行检索,提升了检索效率和准确率,这里 OpenAI 使用的方法就是 HyDE,具体的内容可以参考我之前关于 HyDE 的介绍文章,不过这个不是所有的效果都那么明显,比如说这个案例的某些 case 中。最终没采用…
- Fine Tuning: …成本太高了没采用…
- 调整嵌入内容分块大小: 真正将结果更好嵌入的方式则是通过调整 chunck 大小实现的,这将结果的准确率提升到了 65%。当然,在这个过程中 OpenAI 团队也提到了他们进行了约 20 次左右的迭代调整,所以是个慢工细活。
- 规则和精细化数据处理: 除了通过 RAG 规则的调整之外,在数据处理上也进行了精细化调整。比如说通过交叉编码器等等对结果重排的方式进行优化结果,同时,通过判定模型领域,提供对应 Meta 信息帮助大模型更好的输出结果等方式将结果相应的准确率提升至了 85%。
- 结构化数据优化: 发现数据中包含结构化数据(如表格)在结果中数据处理会有问题,为此定制了数据提取方法通过进一步的数据清洗和预处理,最终将准确率提升至 98%。
这其实是非常值得称道的结果准确率,要知道在这个过程中仅仅通过数据提取和 RAG 进行了优化,就将准确率提升了 53%,而没有采用模型微调等等技术。
案例二:文本生成 SQL
这个案例中的初始效果要比第一个案例好上很多,OpenAI 是从 69% 这个基线开始进行优化。因为 SQL 的格式化相对比较固定,基础模型里面已经包含了所有它需要的大部分知识,其实这个案例中模型微调提供的效果助力更大。不过既然我们这篇文章主要谈一下 RAG 的内容,我们还是继续介绍一下具体的实现方案(注意这里其实有一些数据)。
最开始实现的方式还是 Prompt Engineering和 RAG 方式进行的。通过问题相似性搜索和 HyDE 方式,结果的准确性从 69% 上升到了 80%。但是这个目标准确率是 84%,其实离目标有一些差距。
因此在这个案例中,优化采用了Fine-Tuning进行优化。通过调整 Prompt 和 FT,模型的结果准确性可以达到 81.7%,这比直接使用 RAG 的方式优化要好上不少。在使用模型 Fine-Tuning 后,叠加RAG,那么这个结果就可以达到 83.5%,基本达到了预期。
总结
OpenAI 的分享揭示了 RAG 技术在实际工程应用中的巨大潜力。RAG 并非万能解药,需要与其他技术结合才能发挥最大效用。我们还需要充分理解 OpenAI 提出的优化框架,并结合实际问题选择合适的优化方向和方法。通过不断尝试和评估,开发者能够有效提升 LLM 性能,使其更好地服务于各种实际应用场景。
从实际的实践中,我们也不难总结出一些常见的规律:
- RAG 技术与其他优化技术协同作用,可以有效提升 LLM 性能。
- 优化 LLM 性能是一个迭代的过程,需要不断尝试和评估,才能找到最佳方案。
- 数据质量比数据数量更重要,高质量的数据能够显著提升模型性能。
- 复杂的优化方法并非总是必需的,简单的微调和提示工程也能取得接近最先进技术的效果。
这篇文章主要聊了关于技巧方法的问题,下篇文章的选题已经选好了,聊聊对于大模型的结果评估,毕竟技巧方法虽多,但不是所有场景都适用,建立合理的评估体系才能让你在各个场景中游刃有余。Stay Tuned!